Language Modeling is an important idea behind many Natural Language Processing tasks such as Machine Translation, Spelling Correction, Speech Recognition, Summarization, Question-Answering etc. Some recent applications of Language models involve Smart Reply in Gmail & Google Text suggestion in SMS. This introduction is mostly inspired by Chapter 4 ‘Language Modeling with N-grams’ of book: “Speech and Language Processing” by Daniel Jurafsky & James H. Marti [1]
What is a Language Model?
Basically Language Model assigns a probability to a sentence or a sequence of words. so given a sequence of words
Probability of this sequence of words will be:
$$P(W) = P(w_1,w_2,w_3,w_4,w_5,...,w_n)$$
We can also calculate probability of upcoming word given previous words as:
$$P(w_n) = P(w_n\, | \,w_1,w_2,w_3,w_4,w_5,...,w_{n-1})$$
Lets take an example of sentence “weather is pleasant”. Probability of this sentence will be expressed as:
$$P("weather\, is\, pleasant") = P(weather)\, \times \,P(is\, | \,weather)\, \times \,P(pleasant\, | \,weather\, is)$$
Formally this can be expressed as:
$$P(w_1,w_2,w_3,w_4,w_5,...,w_n) = \prod_{i=1}^n\, P(w_i\, | \,w_1,w_2,w_3,w_4,w_5,...,w_{i-1})$$
But how to calculate this probability?
Markov Assumption
Andrey Markov was a Russian mathematician who described a stochastic process with a property called Markov Property or Markov Assumption. This basically states that one can make predictions for the future of the process based solely on its present state just as well as one could knowing the process’s full history, hence independently from such history.[2]
Based on this assumption we can rewrite conditional probability of ‘pleasant’ as:
$$P(pleasant\, | \,weather\, is) \approx P(pleasant\, | \,weather)$$
Or formally as:
$$P(w_n\, | \,w_1,w_2,w_3,w_4,w_5,...,w_{n-1}) = P(w_n\, | \,w_{n-1})$$
Above equation also represent a Bigram[3] model. In case of N-gram models this assumption can be extended such that conditional probability may depend on couple of previous words as:
$$P(w_n\, | \,w_1,w_2,w_3,w_4,w_5,...,w_{n-1}) = P(w_n\, | \,w_{n-k},...,w_{n-1})$$
Bigram Model
Now lets find probability for simplest model where conditional probability of any word only depends on previous word by Markov assumption.
$$P(w_i\,|\,w_{i-1}) = \frac{count(w_{i-1},w_i)}{count(w_{i-1})}$$
Lets understand this with a small corpus of famous poem ‘A Girl’ by Ezra Pound
The tree has entered my hands,
The sap has ascended my arms,
The tree has grown in my breast-Downward,
The branches grow out of me, like arms.
Tree you are,
Moss you are,
You are violets with wind above them.
A child - so high - you are,
And all this is folly to the world.
Here word ‘arms’ appears after ‘my’ only once but word ‘my’ appeared total three times in poem so Probability of ‘arms’ given ‘my’ is:
$$P(arms\, |\, my) = \frac{1}{3}$$
To calculate probability of first & last word <s> & <\s> are added at start & end of sentence respectively. Similarly probability of sentence or sequence of words can be calculated using above approach by multiplying all Bigram probabilities.
Applications of Language Models
1. Spelling Correction
For spelling correction probability of incorrect sentence will be much smaller then correct sentence
$$P(weather\, is\, \mathbf{pleasent}) > P(weather\, is\, \mathbf{plesen})$$
2. Speech Recognition
As words ‘weather’ & ‘whether’ may have similar phonetics, system may confuse among these but probability of ‘weather is pleasant’ will be higher than ‘whether is pleasant’
$$P(\mathbf{weather}\, is\, pleasant) > P(\mathbf{whether}\, is\, pleasant)$$
3. Machine Translation
Selecting appropriate sequence while translating from one language to another can also use probability of sequence for providing more appropriate translations
$$P(\mathbf{high}\, winds\, tonight) > P(\mathbf{large}\, winds\, tonight)$$
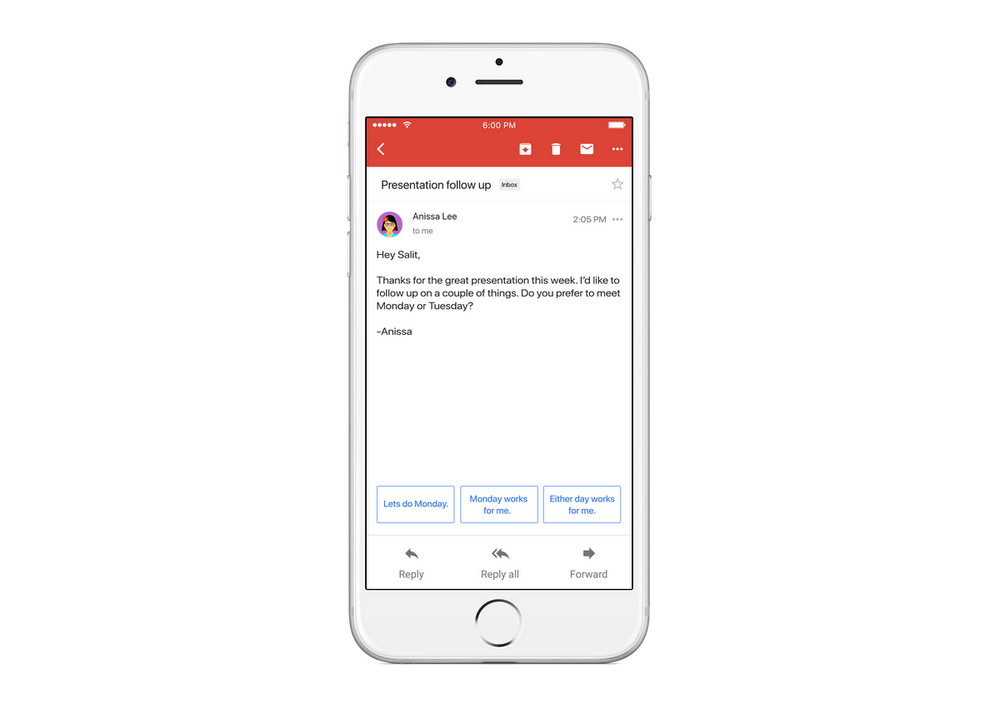
4. Gmail Smart Reply
Complete details of this system are discussed in this paper: “Smart Reply: Automated Response Suggestion for Email” [4]
5. Predictive Text
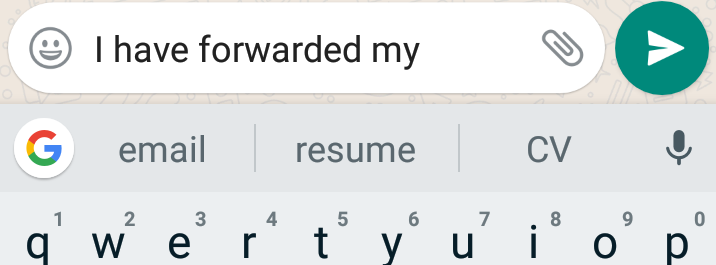
By looking at previous sequence of words language model can predict next word, this feature was recently introduced in android phone keyboard by Google.
Now lets build our own language model for predicting next word using a very small corpus of words. I will build this model using keras & deep neural network architecture with LSTM.
Building Language Model
As Language modeling involves predicting the next word in a sequence given the sequence of words already present we can train a language model to create subsequent words in sequence from given starting sequence.
Sequence Models or Recurrent neural networks, or RNNs[5] are a family of neural networks for processing sequential data. A detailed discussion on Sequence Models is provided in Chapter 10 of Deep Learning Book. [6]
Language model design discussed below is inspired by this insightful article: How to Develop Word-Based Neural Language Models in Python with Keras by Jason Brownlee.
For this language model I will use part of the poem “This Is the House That Jack Built” [7] as training corpus.
This Is the House That Jack Build
data = """ This is the house that Jack built.\n
This is the malt that lay in the house that Jack built.\n
This is the rat that ate the malt\n
That lay in the house that Jack built.\n
This is the cat that killed the rat\n
That ate the malt that lay in the house that Jack built.\n
This is the dog that worried the cat\n
That killed the rat that ate the malt\n
That lay in the house that Jack built.\n
This is the cow with the crumpled horn\n """
Importing Packages
from numpy import array
from keras.preprocessing.text import Tokenizer
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Embedding
from keras.utils.vis_utils import plot_model
from keras_tqdm import TQDMNotebookCallback
import matplotlib.pyplot as plt
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
Procedure to generate sequence
def generate_seq(model, tokenizer, seed_text, n_words):
in_text, result = seed_text, seed_text
# generate a fixed number of words
for _ in range(n_words):
# encode the text as integer
encoded = tokenizer.texts_to_sequences([in_text])[0]
encoded = array(encoded)
# predict a word in the vocabulary
yhat = model.predict_classes(encoded, verbose=0)
# map predicted word index to word
out_word = ''
for word, index in tokenizer.word_index.items():
if index == yhat:
out_word = word
break
# append to input
in_text, result = out_word, result + ' ' + out_word
return result
Integer encoding of text
tokenizer = Tokenizer()
tokenizer.fit_on_texts([data])
encoded = tokenizer.texts_to_sequences([data])[0]
tokens = data.split(" ")
print("Word to Interger mapping of first 6 words:\n")
for i in range(6):
print(tokens[i+1],encoded[i])
Word to Interger mapping of first 6 words:
This 3
is 4
the 1
house 5
that 2
Jack 6
Determining the vocabulary size
vocab_size = len(tokenizer.word_index) + 1
print('Vocabulary Size: %d' % vocab_size)
Vocabulary Size: 21
Creating sequences of words to fit the model with one word as input and one word as output
sequences = list()
for i in range(1, len(encoded)):
sequence = encoded[i-1:i+1]
sequences.append(sequence)
print('Total Sequences: %d' % len(sequences))
print('First 10 Sequences: ',sequences[:10])
Total Sequences: 86
First 10 Sequences: [[3, 4], [4, 1], [1, 5], [5, 2], [2, 6], [6, 7], [7, 3], [3, 4], [4, 1], [1, 8]]
sequences = array(sequences)
X, y = sequences[:,0],sequences[:,1]
print("First 5 Sequence Outputs")
print(y[:5])
y = to_categorical(y, num_classes=vocab_size)
print("\nTheir One Hot encodings:")
print(y[:5])
First 5 Sequence Outputs
[4 1 5 2 6]
Their One Hot encodings:
[[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
Building Model
model = Sequential()
model.add(Embedding(vocab_size, 10, input_length=1))
model.add(LSTM(50))
model.add(Dense(vocab_size, activation='softmax'))
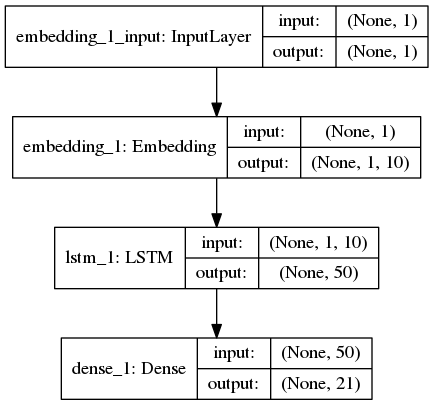
Model Architecture
print(model.summary())
plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 1, 10) 210
_________________________________________________________________
lstm_1 (LSTM) (None, 50) 12200
_________________________________________________________________
dense_1 (Dense) (None, 21) 1071
=================================================================
Total params: 13,481
Trainable params: 13,481
Non-trainable params: 0
_________________________________________________________________
None
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(X, y, epochs=500,
verbose=0,
callbacks=[TQDMNotebookCallback()])
Finally lets generate sequence of 6 words by providing only first letter for sequence
print(generate_seq(model, tokenizer, 'This', 6))
This is the house that jack built
As expected the model generated the most plausible line based on training corpus.
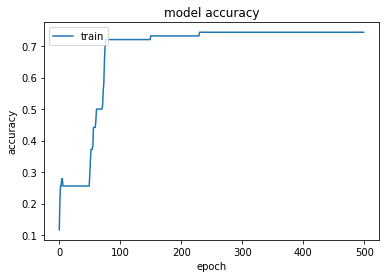
Accuracy & Loss Plots
plt.plot(history.history['acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
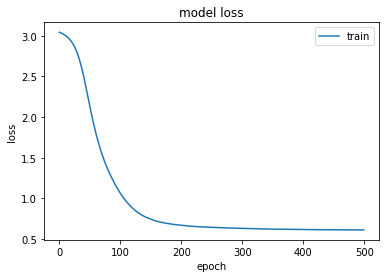
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.show()
Refrences
- Jurafsky, Dan. Speech & language processing. Pearson Education India, 2000.
- https://en.wikipedia.org/wiki/Markov_property
- https://en.wikipedia.org/wiki/Bigram
- Kannan, Anjuli, et al. “Smart reply: Automated response suggestion for email.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
- Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. Learning internal representations by error propagation. No. ICS-8506. California Univ San Diego La Jolla Inst for Cognitive Science, 1985.
- https://en.wikipedia.org/wiki/This_Is_the_House_That_Jack_Built
- http://www.deeplearningbook.org/contents/rnn.html
- https://machinelearningmastery.com/develop-word-based-neural-language-models-python-keras/
Thanks for reading this notebook. I am learning NLP & not an expert in this field, feel free to provide your feedback on errors & improvements.